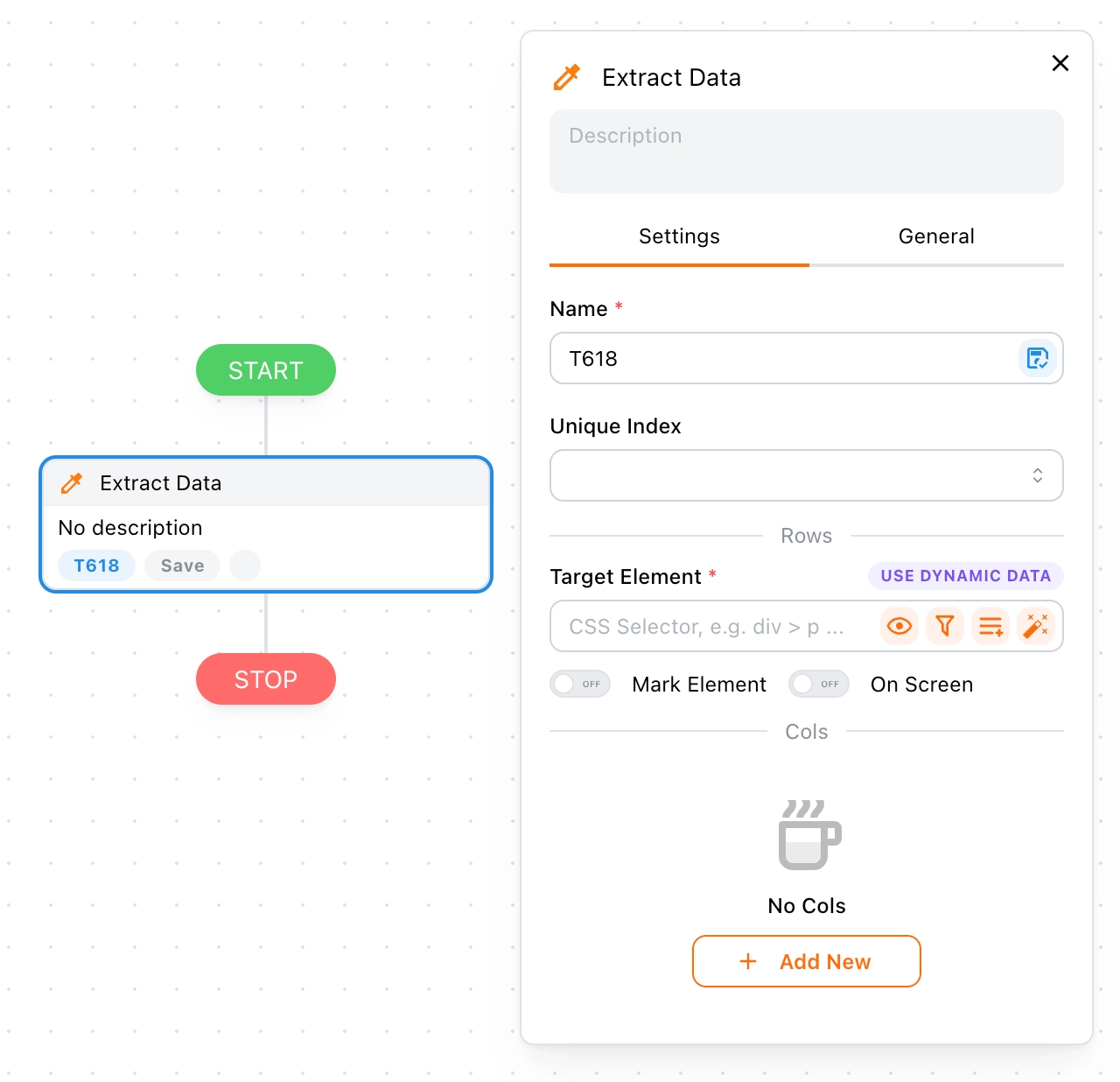
Extract Data
In this section, we will guide you on how to use the Extract Data block.
Use Cases
When you need to extract a large amount of data from a webpage and export it to Excel, you must use this block. Of course, you can also extract data for temporary access (without needing to store it).
💡 Tip:
If you only want to extract a single piece of data from the page, such as a title or a link, it’s better to use the Set Variables block.
Name
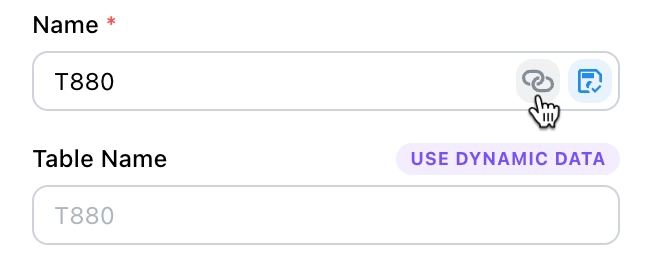
The name is automatically generated, such as T880, but you can change it manually if needed. In most cases, it isn't necessary.
Generally, the name is unique. If the same name is used, the data will be stored in the same table, and the structure will follow the first one defined.
Once the data is successfully extracted, it will be stored in @tables. If needed, you can access it using the Template Syntax.
Example
-
Access all rows of the table:
{{@tables.T880.$rows}} -
Access the number of rows in the table:
{{@tables.T880.$size}}
Table Name
You can specify an actual table name, which is optional. If not provided, the default name will be used as the table name.
This is useful in the following scenarios:
-
Using Date as the Table Name
When you want to automatically store data by the current date, you can use the following expression to achieve this:
{{@funcs.getDate()|format("YYYY-MM-DD")}} // 2024-12-18 {{@funcs.getDate()|format("DDMMMddd")}} // 18DecWedFor more formats, please refer to Day.js。
-
Custom Table Name
If you want to specify a table name each time you run a recipe, you can define a parameter, such as
MyTable, and reference it using the following expression:{{@args.MyTable}}
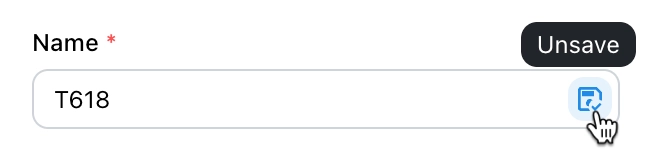
Saving the Table
Notice the small icon on the right side of the image below. When highlighted, it indicates that the data will be saved in the browser once extracted. Otherwise, the data will be saved in memory (for temporary access) and will be destroyed after the task is completed.
❓ Question:
Should I save the data?
If you plan to export the data to Excel, then you should save it.
Merging data
By default, each data extraction overwrites the previous result. When this option is enabled, Tapicker will merge the newly extracted data with the previous result instead of replacing it.
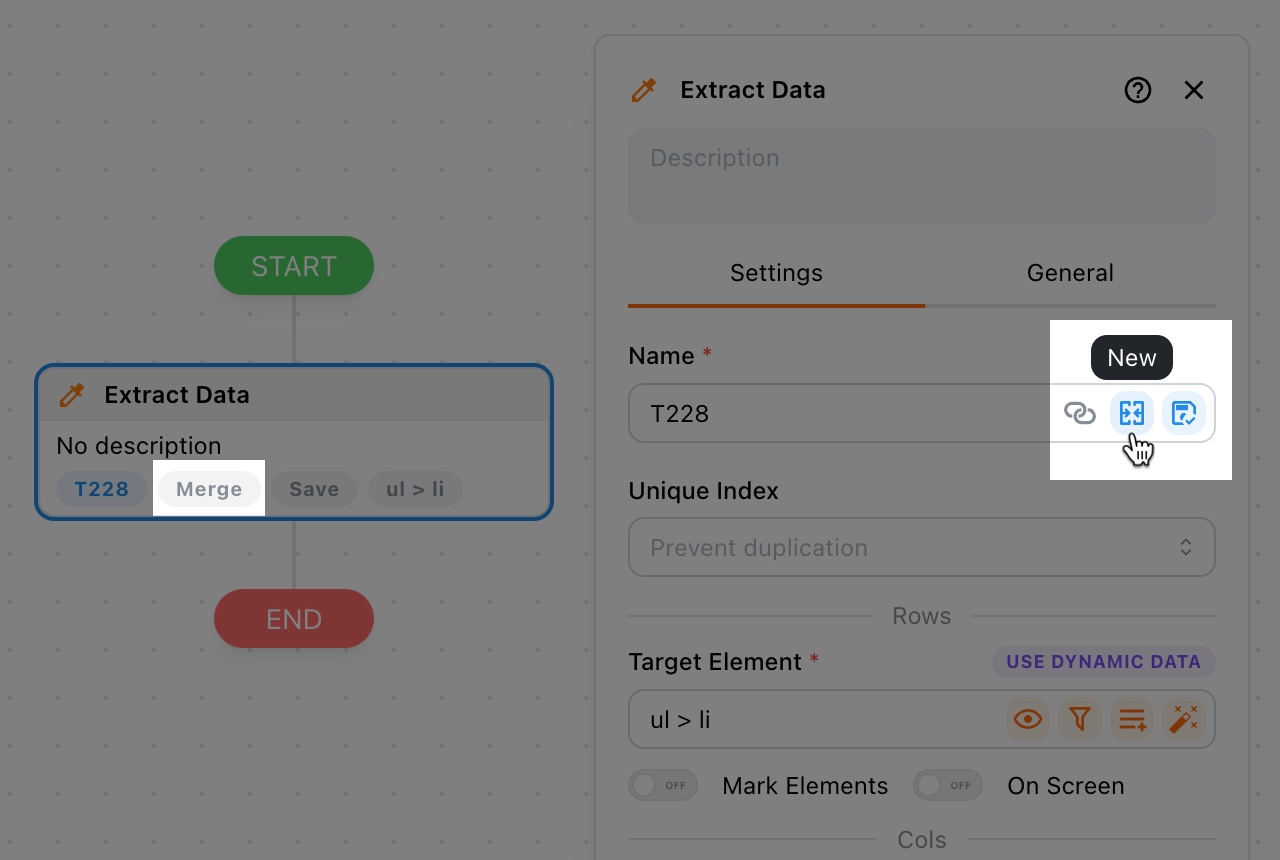
For example: if the first extraction returns 10 rows, and the second extraction also returns 10 rows.
With Merge Data enabled, accessing the data with:
{{@tables.T228.$rows}} // [{...}, {...}, ...20]
{{@tables.T228.$total}} // 20
Without it enabled, you will only get the most recent extraction:
{{@tables.T228.$rows}} // [{...}, {...}, ...10]
{{@tables.T228.$total}} // 10
Note:This option only affects in-memory results. It does not affect the data written to your database.
Table Data Structure
Once data is successfully extracted, it will be saved as an array of objects:
[
{ "Name": "Rose", "Age": "18" },
{ "Name": "Jack", "Age": "20" },
{ "Name": "Molly", "Age": "48" }
]
In Excel, it looks like this:
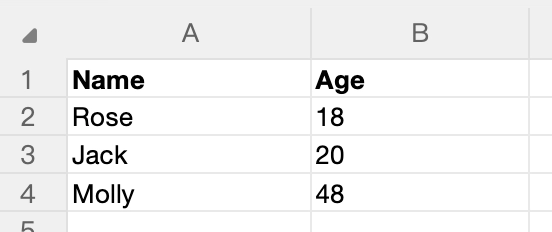
Table Rows
First, you need to set the target element for rows to tell Tapicker where to extract data from. For tips on setting target elements, refer to the Target Element section.
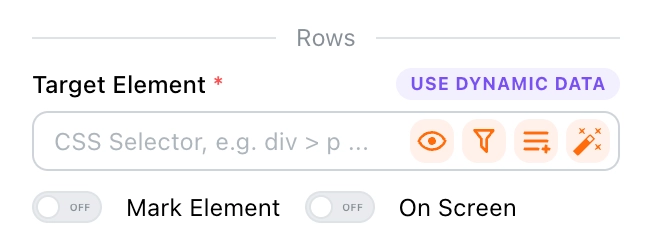
You can click the icon on the far right to open the Finder and quickly select target elements from the page.
Where are the Rows?
In a webpage, rows are abstract. You need to adjust your mindset. Below are examples of how to identify rows.
Take Best Seller Books as an example.
-
List Page:Each book is considered a row of data.

-
Detail Page:The entire page is considered a row of data.

Mark Elements
After successfully extracting data, elements will be marked, and they will be ignored during the next extraction. If you are extracting data from an infinite scroll list, it is recommended to enable this option.
💡 Tip:
Reloading or navigating back on the page will clear the marks.
On Screen
As the name suggests, when this option is enabled, it will only extract elements visible on the screen. If you are extracting data from a virtual list, it is recommended to enable this option.
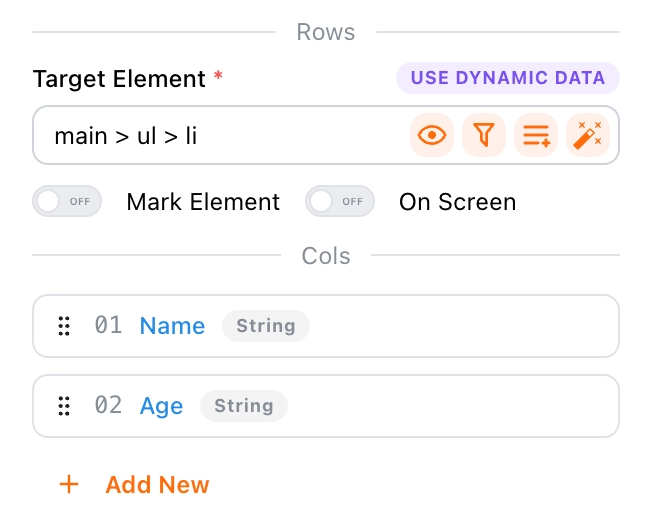
Table Columns
You can add multiple columns to the table as needed. Configuring columns works similarly to defining variables; refer to the Set Variables section for more details.
💡 Tip:
It is highly recommended to set the target element for rows before adding columns. Otherwise, if the target element changes, you will need to reconfigure the column scope.
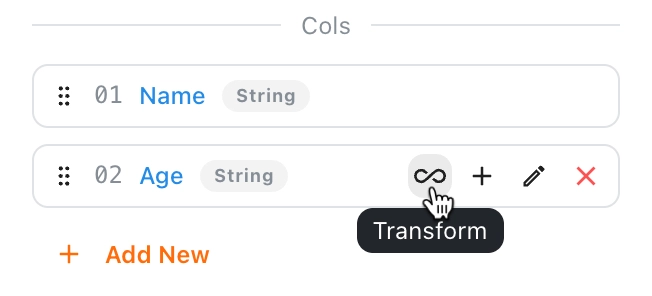
Data Transformation
If the extracted data format does not meet your needs, you can perform data transformation here. Refer to the Data Transformation section for more information.
Unique Index
You can set a unique index to prevent duplicate data. For example, if you set Name as the unique index, the data will be checked for duplicates before being stored. Duplicate data will be discarded.
💡 Tip:
If duplicate data already exists in the database, adding a unique index will not remove the duplicates.
Adding a unique index can impact data collection efficiency, so it’s not recommended unless necessary.
If data is cleared or deleted, the unique index will be rebuilt.